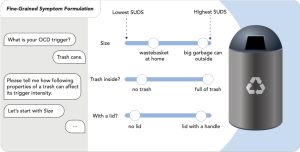
Obsessive-compulsive disorder (OCD) is a mental health condition that significantly impacts people’s quality of life. To better understand the challenges and needs in OCD self-management, we conducted interviews with 10 participants with diverse OCD conditions and seven therapists specializing in OCD treatment. Through these interviews, we explored the characteristics of participants’ triggers and how they shaped their compulsions, and uncovered key coping strategies across different stages of OCD episodes.
Obsessive-compulsive disorder (OCD) is a mental health condition that significantly impacts people’s quality of life. While evidence-based therapies such as exposure and response prevention (ERP) can be effective, managing OCD symptoms in everyday life—an essential part of treatment and independent living—remains challenging due to fear confrontation and lack of appropriate support. To better understand the challenges and needs in OCD self-management, we conducted interviews with 10 participants with diverse OCD conditions and seven therapists specializing in OCD treatment. Through these interviews, we explored the characteristics of participants’ triggers and how they shaped their compulsions, and uncovered key coping strategies across different stages of OCD episodes. Our findings highlight critical gaps between OCD self-management needs and currently available support. Building on these insights, we propose design opportunities for just-in-time self-management technologies for OCD, including personalized symptom tracking, just-in-time interventions, and support for OCD-specific privacy and social needs—through technology and beyond.
Publication accepted to ASSETS 2025 and presented in Denver, Colorado, USA.
We explored people with disabilities’ avatar perception and disability disclosure preferences in social VR by (1) conducting a systematic review of fifteen popular social VR applications to evaluate their avatar diversity and accessibility support and (2) interviewing 19 participants with different disabilities to understand their avatar experiences (Zhang et al. 2022).
In social Virtual Reality (VR), users are embodied in avatars and interact with other users in a face-to-face manner using avatars as the medium. With the advent of social VR, people with disabilities (PWD) have shown an increasing presence on this new social media. With their unique disability identity, it is not clear how PWD perceive their avatars and whether and how they prefer to disclose their disability when presenting themselves in social VR. We fill this gap by exploring PWD’s avatar perception and disability disclosure preferences in social VR. Our study involved two steps. We first conducted a systematic review of fifteen popular social VR applications to evaluate their avatar diversity and accessibility support. We then conducted an in-depth interview study with 19 participants who had different disabilities to understand their avatar experiences. Our research revealed a number of disability disclosure preferences and strategies adopted by PWD (e.g., reflect selective disabilities, present a capable self). We also identified several challenges faced by PWD during their avatar customization process. We discuss the design implications to promote avatar accessibility and diversity for future social VR platforms.
Publication accepted to ASSETS 2022 and presented in Athens, Greece.
We conducted a diary study with 10 People with Disabilities who freely explored VRChat for two weeks, comparing their experiences between using regular avatars and avatars with disability signifiers (i.e., avatar features that indicate the user’s disability in real life) (Zhang et al. 2023).
People with disabilities (PWD) have shown a growing presence in the emerging social virtual reality (VR). To support disability representation, some social VR platforms start to involve disability features in avatar design. However, it is unclear how disability disclosure via avatars (and the way to present it) would affect PWD’s social experiences and interaction dynamics with others. To fill this gap, we conducted a diary study with 10 PWD who freely explored VRChat—a popular commercial social VR platform—for two weeks, comparing their experiences between using regular avatars and avatars with disability signifiers (i.e., avatar features that indicate the user’s disability in real life). We found that PWD preferred using avatars with disability signifiers and wanted to further enhance their aesthetics and interactivity. However, such avatars also caused embodied, explicit harassment targeting PWD. We revealed the unique factors that led to such harassment and derived design implications and protection mechanisms to inspire more safe and inclusive social VR.
Publication accepted to ASSETS 2023 and presented in New York City, New York.
While extended reality (XR) technology is seeing increasing mainstream utilization, it is not accessible to users with disabilities and lacks support for XR developers to create accessibility features. In this study, we investigated XR developers’ practices, challenges, needs when integrating accessibility in their projects. Our findings revealed developers’ needs for open-source accessibility support, such as code examples of particular accessibility features alongside accessibility guidelines.
Publication accepted to IEEE VR 2023 and presented as a workshop in Shanghai, China.
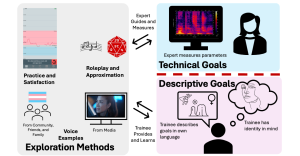
We interviewed six voice experts and ten transgender individuals with voice training experience (voice trainees), focusing on how they defined, triangulated, and used voice goals. We found that goal voice exploration involves navigation between approximate and clear goals, and continuous reevaluation throughout the voice training journey. Our study reveals how voice examples, character descriptions, and voice modification and training technologies inform goal exploration, and identifies risks of overemphasizing goals.
Abstract: Gender-affirming voice training is critical for the transition process for many transgender individuals, enabling their voice to align with their gender identity. Individualized voice goals guide and motivate the voice training journey, but existing voice training technologies fail to define clear goals. We interviewed six voice experts and ten transgender individuals with voice training experience (voice trainees), focusing on how they defined, triangulated, and used voice goals. We found that goal voice exploration involves navigation between approximate and clear goals, and continuous reevaluation throughout the voice training journey. Our study reveals how voice examples, character descriptions, and voice modification and training technologies inform goal exploration, and identifies risks of overemphasizing goals. We identified technological implications informed by the separation of voice goals and targets, and provide guidelines for for supporting individualized goals throughout the voice training journey based on brainstorming with trainees and experts.
We systematically collected 373 ADHD-relevant videos with comments from YouTube and TikTok and analyzed the data with a mixed method. Our study identified the characteristics of ADHD-relevant videos on VSPs (e.g., creator types, video presentation forms, quality issues) and revealed the collective efforts of creators and viewers in video quality control, such as authority building, collective quality checking, and accessibility improvement.
Video-sharing platforms (VSPs) have become increasingly important for individuals with ADHD to recognize symptoms, acquire knowledge, and receive support. While videos offer rich information and high engagement, they also present unique challenges, such as information quality and accessibility issues to users with ADHD. However, little work has thoroughly examined the video content quality and accessibility issues, the impact, and the control strategies in the ADHD community. We fill this gap by systematically collecting 373 ADHD-relevant videos with comments from YouTube and TikTok and analyzing the data with a mixed method. Our study identified the characteristics of ADHD-relevant videos on VSPs (e.g., creator types, video presentation forms, quality issues) and revealed the collective efforts of creators and viewers in video quality control, such as authority building, collective quality checking, and accessibility improvement. We further derive actionable design implications for VSPs to offer more reliable and ADHD-friendly content.
Publication accepted to ASSETS 2025 and presented in Denver, Colorado, USA
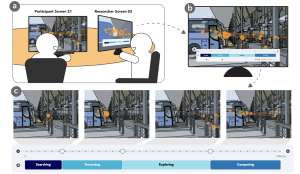
We conducted a retrospective think-aloud study using eye tracking with 20 low vision participants and 20 sighted controls. Participants completed various image-viewing tasks and watched the playback of their gaze trajectories to reflect on their visual experiences. Based on the study, we derived a visual intent taxonomy with five visual intents characterized by participants’ gaze behaviors. We demonstrated the difference between low vision and sighted participants’ gaze behaviors and how visual ability affected low vision participants’ gaze patterns across visual intents.
Accessing visual information is crucial yet challenging for people with low vision due to visual conditions like low visual acuity and limited visual fields. However, unlike blind people, low vision people have and prefer using their functional vision in daily tasks. Gaze patterns thus become an important indicator to uncover their visual challenges and intents, inspiring more adaptive visual support. We seek to deeply understand low vision users’ gaze behaviors in different image-viewing tasks, characterizing typical visual intents and the unique gaze patterns exhibited by people with different low vision conditions. We conducted a retrospective think-aloud study using eye tracking with 20 low vision participants and 20 sighted controls. Participants completed various image-viewing tasks and watched the playback of their gaze trajectories to reflect on their visual experiences. Based on the study, we derived a visual intent taxonomy with five visual intents characterized by participants’ gaze behaviors. We demonstrated the difference between low vision and sighted participants’ gaze behaviors and how visual ability affected low vision participants’ gaze patterns across visual intents. Our findings underscore the importance of combining visual ability information, visual context, and eye tracking data in visual intent recognition, setting up a foundation for intent-aware assistive technologies for low vision people.
Publication accepted to ASSETS 2025 and presented in Denver, Colorado, USA.
We present CookAR, a head-mounted AR system with real-time object affordance augmentations to support safe and efficient interactions with kitchen tools. To design and implement CookAR, we collected and annotated the first egocentric dataset of kitchen tool affordances, fine-tuned an affordance segmentation model, and developed an AR system with a stereo camera to generate visual augmentations.
Abstract: Cooking is a central activity of daily living, supporting independence as well as mental and physical health. However, prior work has highlighted key barriers for people with low vision (LV) to cook, particularly around safely interacting with tools, such as sharp knives or hot pans. Drawing on recent advancements in computer vision (CV), we present CookAR, a head-mounted AR system with real-time object affordance augmentations to support safe and efficient interactions with kitchen tools. To design and implement CookAR, we collected and annotated the first egocentric dataset of kitchen tool affordances, fine-tuned an affordance segmentation model, and developed an AR system with a stereo camera to generate visual augmentations. To validate CookAR, we conducted a technical evaluation of our fine-tuned model as well as a qualitative lab study with 10 LV participants for suitable augmentation design. Our technical evaluation demonstrates that our model outperforms the baseline on our tool affordance dataset, while our user study indicates a preference for affordance augmentations over the traditional whole object augmentations.
We interviewed 26 first responders in the field who experienced a state-of-the-art optical-see-through AR HMD, soliciting their first-hand experiences, design ideas, and concerns on its interaction techniques and four types of AR cues (Zhang et al. 2024).
Kexin Zhang, Brianna R Cochran, Ruijia Chen, Lance Hartung, Bryce Sprecher, Ross Tredinnick, Kevin Ponto, Suman Banerjee, Yuhang Zhao
First responders (FRs) navigate hazardous, unfamiliar environments in the field (e.g., mass-casualty incidents), making life-changing decisions in a split second. AR head-mounted displays (HMDs) have shown promise in supporting them due to its capability of recognizing and augmenting the challenging environments in a hands-free manner. However, the design space has not been thoroughly explored by involving various FRs who serve different roles (e.g., firefighters, law enforcement) but collaborate closely in the field. We interviewed 26 first responders in the field who experienced a state-of-the-art optical-see-through AR HMD, as well as its interaction techniques and four types of AR cues (i.e., overview cues, directional cues, highlighting cues, and labeling cues), soliciting their first-hand experiences, design ideas, and concerns. Our study revealed both generic and role-specific preferences and needs for AR hardware, interactions, and feedback, as well as identifying desired AR designs tailored to urgent, risky scenarios (e.g., affordance augmentation to facilitate fast and safe action). While acknowledging the value of AR HMDs, concerns were also raised around trust, privacy, and proper integration with other equipment. Finally, we derived comprehensive and actionable design guidelines to inform future AR systems for in-field FRs.
Publication accepted to CHI 2024 and presented in Honolulu, Hawaii.
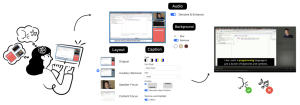
While videos have become increasingly prevalent in delivering information across different educational and professional contexts, individuals with ADHD often face attention challenges when watching informational videos due to the dynamic, multimodal, yet potentially distracting video elements. To understand and address this critical challenge, we designed FocusView, a video customization interface that allows viewers with ADHD to customize informational videos from different aspects. We evaluated FocusView with 12 participants with ADHD and found that FocusView significantly improved the viewability of videos by reducing distractions. Through the study, we uncovered participants’ diverse perceptions of video distractions (e.g., background music as a distraction vs. stimulation boost) and their customization preferences, highlighting unique ADHD-relevant needs in designing video customization interfaces (e.g., reducing the number of options to avoid distraction caused by customization itself). We further derived design considerations for future video customization systems for the ADHD community.
Publication accepted to ASSETS 2025 and presented in Denver, Colorado, USA